
Spark, RStudio and Shiny servers in a docker cluster hosted by Carina
Summary
The objective of this blog is demonstrate that the integration of a Spark master node, RStudio and Shiny servers is possible in a docker image. An indefinite number of Spark worker nodes moreover can be deployed using the same image. In addition, a toy example of a Shiny application powered by SparkR is included.
Introducction
SparkR
SparkR is an R package designed to use Apache Spark from the R command line and to allow distributed computations on large datasets. Importantly, the distributed machined learning library MLlib can be utilized in SparkR. For training proposes, it can be run in “standalone mode”, which means using a single node, probably your own computer.
My personal experience is that not all the programs or applications developed in standalone mode will work in a fully integrated cluster mode. Therefore, SparkR should be deployed in a cluster to obtain its full potential.
It is interesting to mention that the deployment Spark has been previosly described on Digital Ocean (here), EC2 (see here), Google cloud (see here) or Azure (see here). Moreover, the integration of SparkR and Rstudio on AWS EC2 has been described extensively here, even including the use of SparkR to power shiny applications link.
I would like to highlight the last two blogs since they have been an important inspiration for this blog. The problem implementing SparkR on a cluster environment such as AWS EC2 is that a deep knowledge of cluster deployment is needed, and installing Spark is not straightforward.
Docker
A potential solution is Docker, an open source project to automatically deploy applications into “containers”. These containers are based on images which contain a root file system and several execution parameters to constitute an independent virtualized operating system. From the docker website: “The concept is borrowed from Shipping Containers, which define a standard to ship goods globally. Docker defines a standard to ship software”. In this link, an example of using a dockerized RStudio Server can be found.
Carina
Even though AWS, Google Cloud, Microsoft Azure and others providers offer interesting quotes, it would be better if SparkR could be run in a cloud environment for free. Carina is a docker environment based on Docker Swarm and it can be used to deploy an application using docker containers in a cluster. Each cluster of Carina is composed of 3 nodes with a capacity of 4 GB and 12 vCPUs each, thus, every cluster has total 12 GBs of RAM and 36 vCPUs. Carina offered free accounts at the time when this file was written (20/07/2016). For more details, go to the Carina website.
One process vs one application per container
Docker strongly advises a one process per container rule, however, there is a tendency to use multiple services in one container while moving to “one application per container” rule (see this blog). To handle the multiple service pero container, the application supervisor can be used as described on the Docker web site here.
This technology has also been used to deploy a Spark server cluster composed of a master node and an indefinite number of slave nodes here. This last application has been fundamental for the development of our image and the Spark server.
Furthemore, RStudio and Shiny servers can be hosted simultaneously in the same cluster to test our SparkR applications and even publish them. To our knowledge, there is no other docker image able to integrate Spark, RStudio and Shiny servers in a cluster mode. Futhermore, we did’t find any other free alternative to Carina as we propose using in this blog.
Getting started
To get started in 15 minutes, follow the subsequent instructions. For a more detailed description, go to here.
1. Sign up for the Carina Beta here.
2. Create a Carina cluster and scale up to 3 nodes
3. Connect to your Carina cluster as explained in here.
If everything runs smoothly, you should see something like this after the docker info command:
$ docker info
Containers: 5
Running: 3
Paused: 0
Stopped: 2
Images: 5
Server Version: swarm/1.2.0
Role: primary
Strategy: spread
Filters: health, port, dependency, affinity, constraint
Nodes: 1
1dba0f72-75bc-4825-a5a0-b2993c535599-n1: 172.99.70.6:42376
└ Status: Healthy
└ Containers: 5
└ Reserved CPUs: 0 / 12
└ Reserved Memory: 0 B / 4.2 GiB
└ Labels: com.docker.network.driver.overlay.bind_interface=eth1, executiondriver=, kernelversion=3.18.21-2-rackos, operatingsystem=Debian GNU/Linux 7 (wheezy) (containerized), storagedriver=aufs
└ Error: (none)
└ UpdatedAt: 2016-05-27T19:27:24Z
└ ServerVersion: 1.11.2
4. Run the following commands:
## Define a network
docker network create spark_network
## Create data volume container with a folder to share among the nodes
docker create --net spark_network --name data-share \
--volume /home/rstudio/share angelsevillacamins/spark-rstudio-shiny
## Deploy master node
docker run -d --net spark_network --name master \
-p 8080:8080 -p 8787:8787 -p 80:3838 \
--volumes-from data-share \
--restart=always \
angelsevillacamins/spark-rstudio-shiny /usr/bin/supervisord --configuration=/opt/conf/master.conf
## Changing permissions in the share folder of the data volume
docker exec master chmod a+w /home/rstudio/share
## Deply worker01 node
docker run -d --net spark_network --name worker01 \
--volumes-from data-share \
--restart=always \
angelsevillacamins/spark-rstudio-shiny /usr/bin/supervisord --configuration=/opt/conf/worker.conf
## Changing permissions in the share folder of the data volume
docker exec worker01 chmod a+w /home/rstudio/share
## Deploy worker02 node
docker run -d --net spark_network --name worker02 \
--volumes-from data-share \
--restart=always \
angelsevillacamins/spark-rstudio-shiny /usr/bin/supervisord --configuration=/opt/conf/worker.conf
## Changing permissions in the share folder of the data volume
docker exec worker02 chmod a+w /home/rstudio/share
After each docker run command, you should see the volume name such as:
c3673ae185b6966d77d193365e8ede1017f4c5a8c4543564565465677e65bd61e
5. Check master external IP with the following command:
docker ps
or go to the Carina Clusters page and press Edit Cluster. The IP should be in the containers description of your master node:
8787 → 146.20.00.00:8787
8080 → 146.20.00.00::8080
3838 → 146.20.00.00:80
6. Launch your favorite web browser and use the previous addresses, taking into account that:
-
Shiny server should be directly accessible with the IP, thus, http://your.ip.as.above.
-
Spark server should be accessible using the port 8080, thus, http://your.ip.as.above:8080.
-
R Studio server should be accessible using the port 8787, thus, http://your.ip.as.above:8787.
glm-sparkr-docker: a Shiny application example
To install this application go to here.
For a more detailed explanation go to here.
If you can’t wait, you can test this application using the following link.
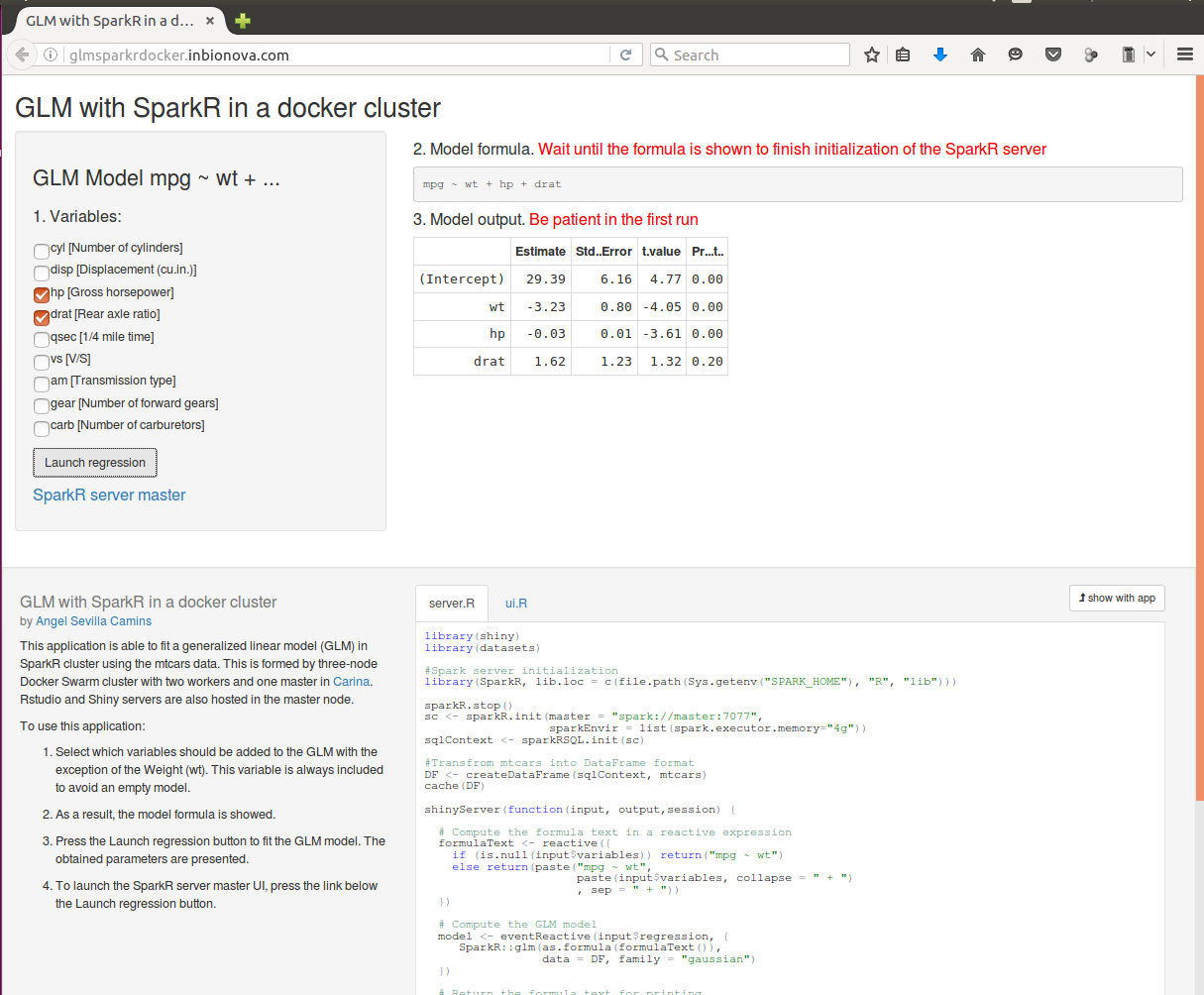
To use this application:
-
Wait until SparkR is initialized. This operation takes about a minute, so PLEASE BE PATIENT. As a result, the model formula is shown.
-
Select the variables that should be added to the linear model with the exception of the Weight (wt). This variable is always included to avoid an empty model.
-
Press the launch regression button to fit the linear model. PLEASE BE PATIENT, the first time takes about 30 seconds.
-
The obtained parameters are shown.
-
This operation can be repeated with different combinations of the variables.
-
To launch the SparkR server master UI, press the link below the Launch regression button.
-
Close the application web page to stop the SparkR connection.
Final remarks
In this blog, a docker image which integrates Spark, RStudio and Shiny servers has been described. Moreover, we have presented glm-sparkr-docker, a toy Shiny application able to use SparkR to fit a generalized linear model in a dockerized Spark server hosted for free by Carina. Although using a docker image with several services is not appropriate for deployment, I think that this image could be very useful for development proposes.